I was trying to understand about SPDY protocol. I couldnt find simple tutorial about “what is SPDY protocol?” and “Why SPDY”. So thought of writing one.
As the name implies, it makes the webpages to load faster.
Why SPDY protocol?
-
Many resources per page:
For any webpage, The avg number of requests per page and the content size that needs to be downloaded has increased drastically over the past decade. It results in high latency.
-
Problems with <=HTTP1.1 protocol
- HTTP does not have multiplexing
- HTTP pipelining is susceptible to head of line blocking (http://en.wikipedia.org/wiki/Head-of-line_blocking) at the HTTP transaction level
- verbose headers
- \r\n in each line of header
Sample HTTP Header
GET /blog/ HTTP/1.1
Host: ramandv.com
Connection: keep-alive
Cache-Control: no-cache
Pragma: no-cache
Accept: text/html,application/xhtml+xml,application/xml;
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36
Referer: http://ramandv.com/blog/wp-admin/post-new.php
Accept-Encoding: gzip,deflate,sdch
Accept-Language: en-US,en;q=0.8
-
TCP Slow start :
TCP is designed to probe the network to figure out the available capacity. So, to use full capacity the connection should exists for longer time. But currently, the HTTP connections dies after downloading a image or js or html files. So, before the TCP starts using full capacity, the TCP connection dies.
Current workaround to sove HTTP problem:
Avoiding multiple HTTP requests by
- Concatenating js, css files
- Image spriting
- Resource inlining
Increase the number of parallel requests to download faster
What is SPDY protocol?
SPDY is an application-layer protocol for transporting content over the web, designed specifically for minimal latency.
Features of SPDY :
[from Chromium SPDY white paper]
Basic features
Multiplexed streams
SPDY allows for unlimited concurrent streams over a single TCP connection. Because requests are interleaved on a single channel, the efficiency of TCP is much higher: fewer network connections need to be made, and fewer, but more densely packed, packets are issued.
Request prioritization
Although unlimited parallel streams solve the serialization problem, they introduce another one: if bandwidth on the channel is constrained, the client may block requests for fear of clogging the channel. To overcome this problem, SPDY implements request priorities: the client can request as many items as it wants from the server, and assign a priority to each request. This prevents the network channel from being congested with non-critical resources when a high priority request is pending.
HTTP header compression
SPDY compresses request and response HTTP headers, resulting in fewer packets and fewer bytes transmitted.
Advanced features
In addition, SPDY provides an advanced feature, server-initiated streams. Server-initiated streams can be used to deliver content to the client without the client needing to ask for it. This option is configurable by the web developer in two ways:
Server push
SPDY experiments with an option for servers to push data to clients via the X-Associated-Content header. This header informs the client that the server is pushing a resource to the client before the client has asked for it. For initial-page downloads (e.g. the first time a user visits a site), this can vastly enhance the user experience.
Server hint
Rather than automatically pushing resources to the client, the server uses the X-Subresources header to suggest to the client that it should ask for specific resources, in cases where the server knows in advance of the client that those resources will be needed. However, the server will still wait for the client request before sending the content. Over slow links, this option can reduce the time it takes for a client to discover it needs a resource by hundreds of milliseconds, and may be better for non-initial page loads.
BTW, SPDY v2 has been adopted for HTTP2.0
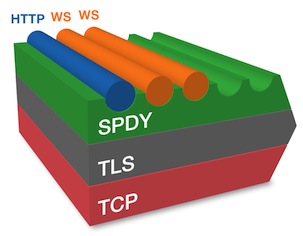
TCP, TLS, SPDY and HTTP relation
Currently, SPDY protocol is being supported in port 443. It could have been implemented in other ports, but because of the risk of that port being firewalled and transparent proxy issues, port 443 is being used.
During the TLS handshake (specifically ClientHello and ServerHello), TLS extension Next Protocol Negotiation (NPN) is used for the server to advertise a list of protocols it supports. As of now www.google.com is sending spdy/3 spdy/2 http/1.1. The client chooses which to use.
If a spdy protocol is selected, TLS transports SPDY. If http/1.1 was chosen, TLS transports HTTP, as it does for regular https sites. If a client does not advertise that is supports NPN the server should assume an http/1.1 connection.
Can I use the SPDY protocol?
Many web servers supports SPDY
How to know the SPDY protocol support?
Use the following addons, to know whether a site supports SPDY or not.
- Chrome SPDY indicator
- Firefox indicator
- Opera indicator
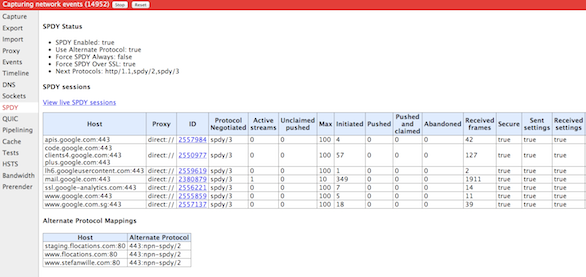
In addition to this, Chrome helps to view the SPDY sessions in the chrome browser, just type the following URL
chrome://net-internals#spdy